Training AI agents to actually support customers
A 3-level hierarchical multi-agent RL environment — support agent, supervisor, manager — trained end-to-end with GRPO on real Indian enterprise support scenarios including Hinglish, policy drift, and live DB lookups.
3-level hierarchy that mirrors human orgs
Every L1 action is held pending until L2 reviews it. Agents can't skip the loop. Authority is enforced, not optional.
- Respond & info-gather
- Query live order DB
- Issue refund ≤ ₹500
- Escalate to L2
Empathy 30% · Accuracy 25% · Resolution 25% · Efficiency 20%
- Approve or reject L1 action
- Give corrective feedback
- Adjust refund ceiling
- Escalate to L3
Oversight quality 35% · Escalation fit 30% · Policy 20%
- Final policy authority
- Approve large refunds
- Override L2 decisions
- Resolve VIP tickets
Decision quality 45% · Resolution 30% · Decisiveness 25%
+15–19pp over every baseline
An 8B model trained with GRPO curriculum outperforms the 70B NIM baseline by 15–19 percentage points — at 8.75× smaller size.
Real GRPO run — 40 steps logged
Qwen2.5-1.5B · Colab T4 · 40 steps · curriculum_basic · 0.6% mean invalid
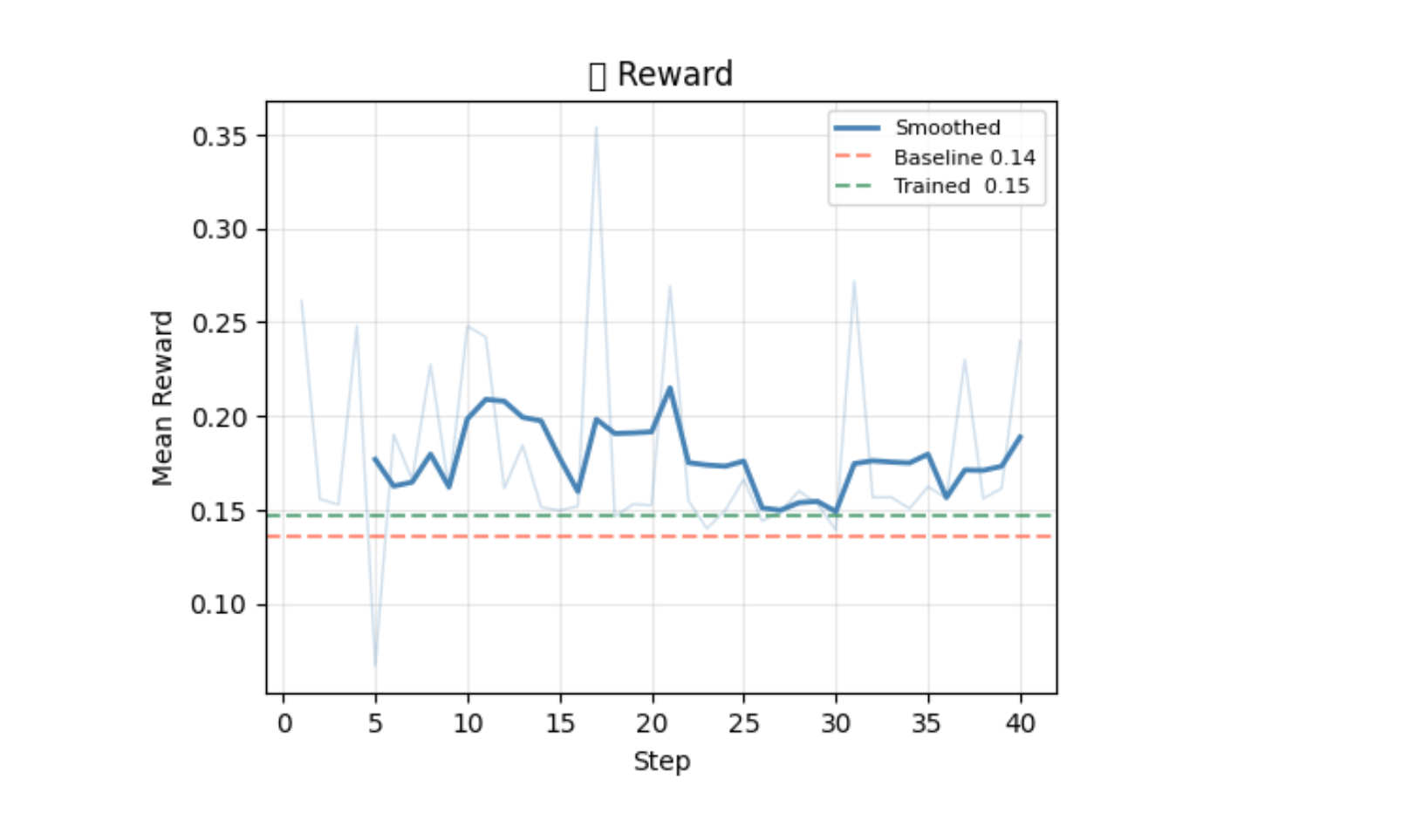
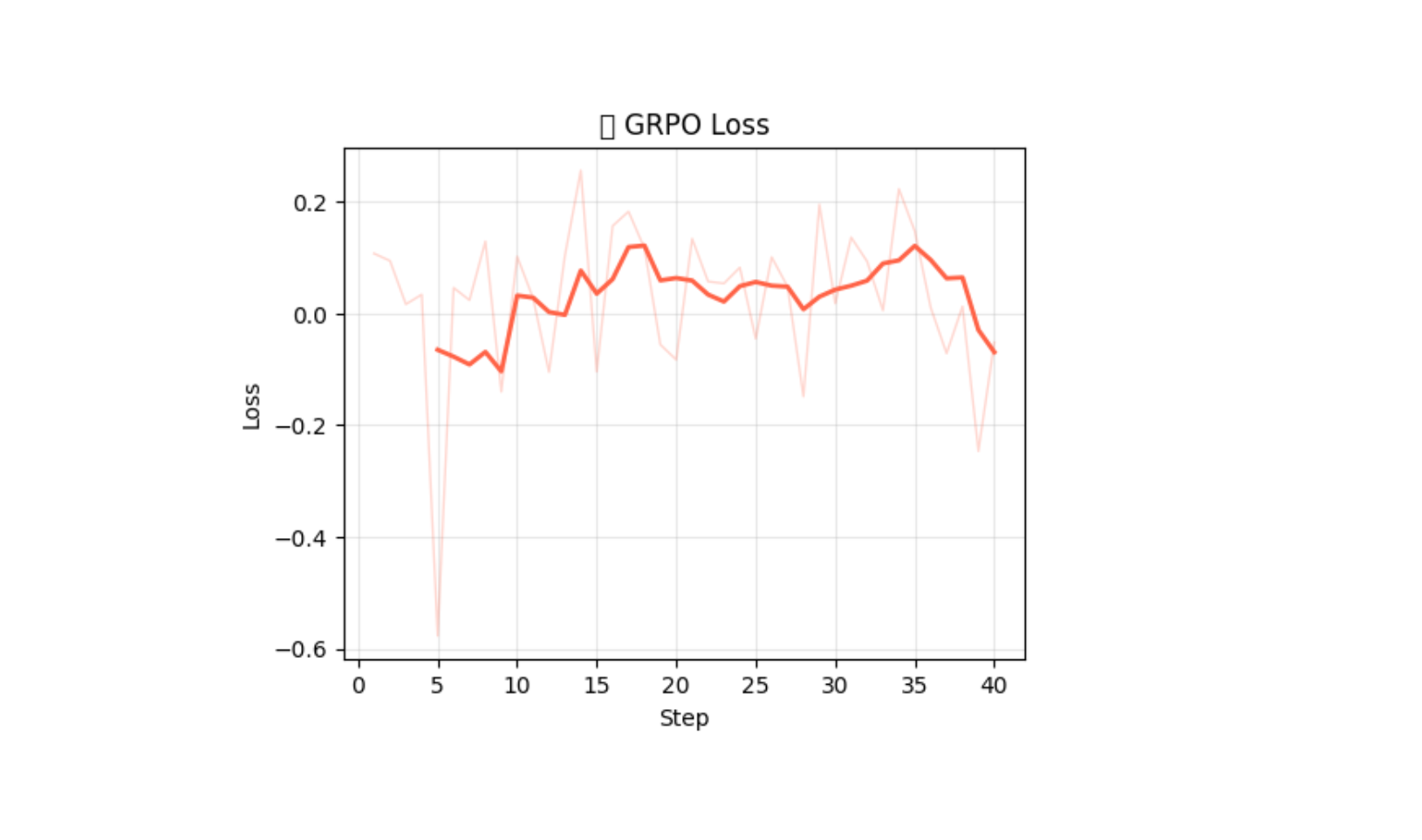
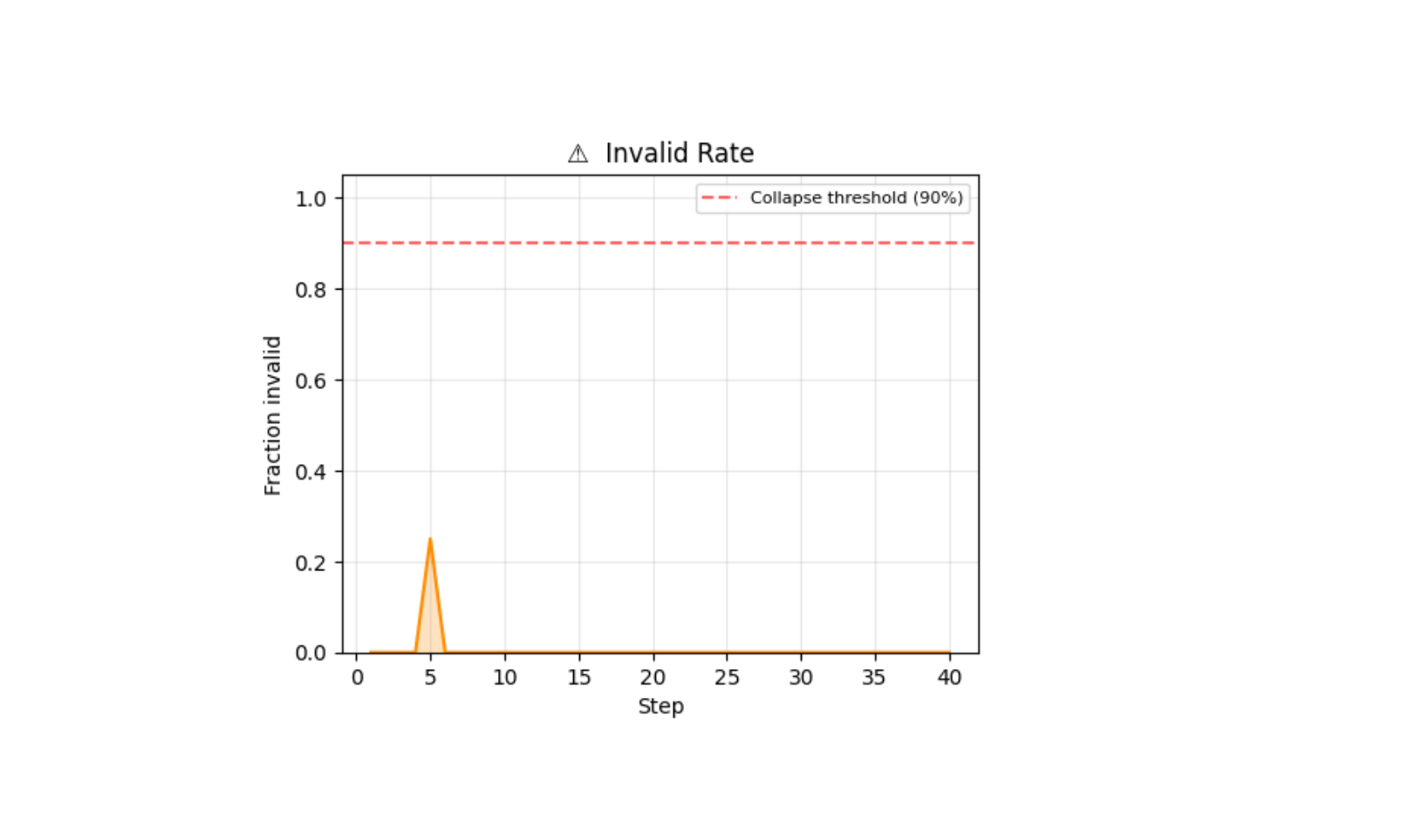
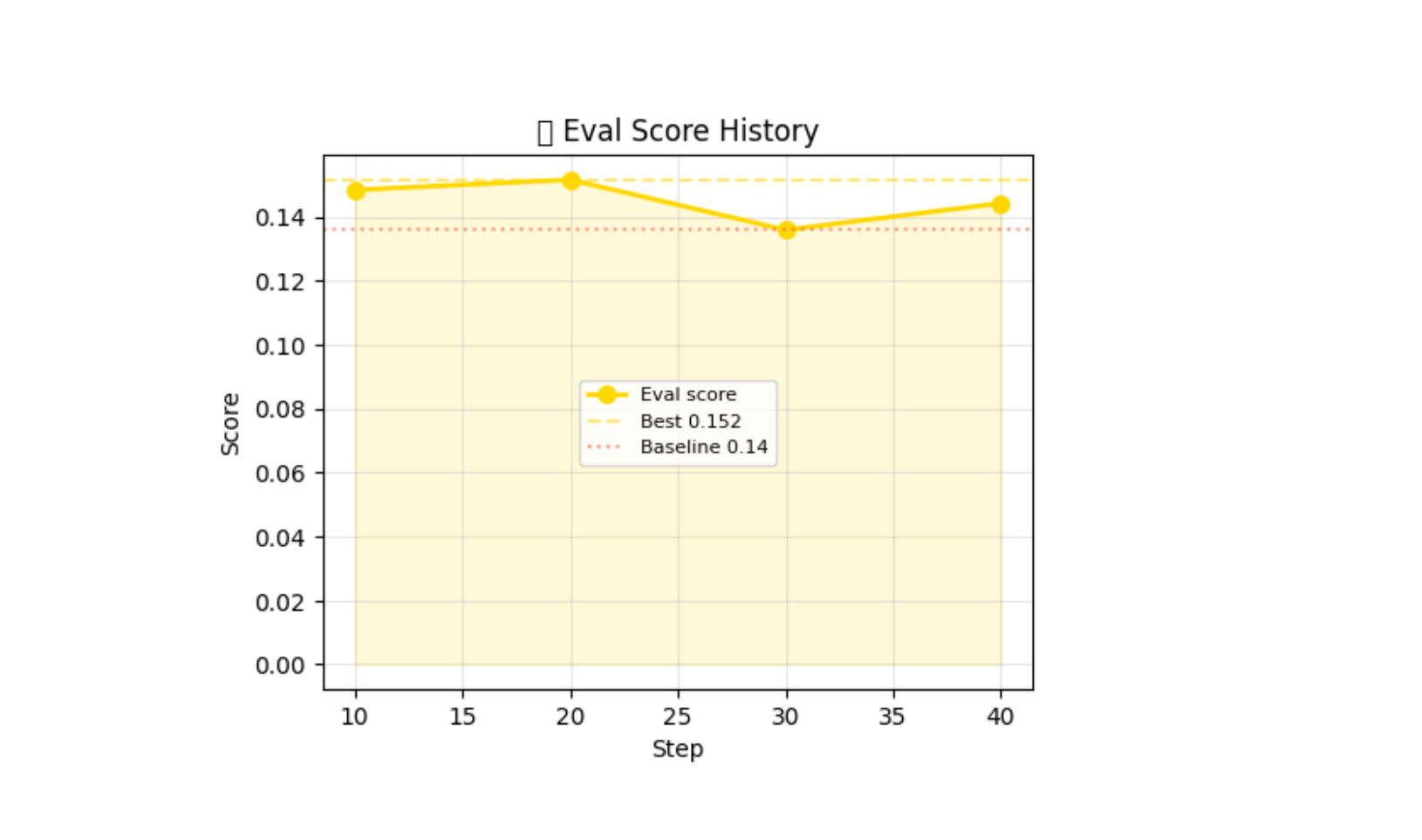
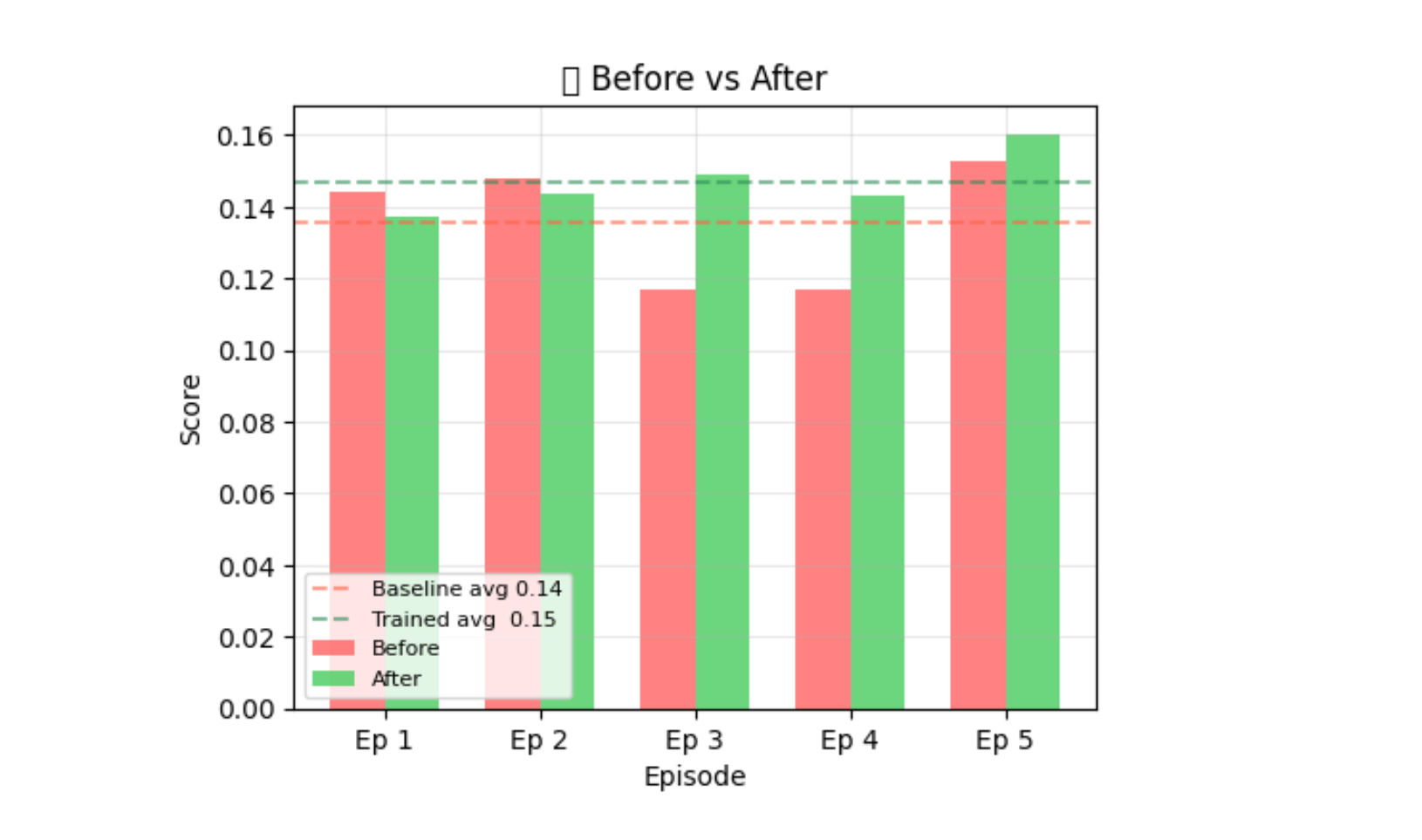
Full L40S run (Llama-3.1-8B, 150 steps): reward reached 0.709 with final=1.000 episodes on curriculum_supervisor · Best checkpoint: 0.531 @ step 40